
Pillbox ya disponible: dale memoria persistente a tu agente
Índice
Introducción
Lo prometido es deuda. En el artículo anterior sobre Pillbox contaba que el proyecto estaba en desarrollo activo y que el lanzamiento público estaba cerca. Pues bien, ya está aquí.
Pillbox está disponible para descargar y usar.
Si no conoces el proyecto, el artículo anterior es el punto de partida: explica el problema que resuelve, la metáfora del pastillero y la filosofía detrás. No voy a repetir todo eso aquí. Este artículo es para hablar de lo que hay ahora: qué hay dentro del sistema de memoria persistente, cómo está construido, y cómo empezar a usarlo hoy.
El motor de memoria persistente
Pillbox es un binario único escrito en Rust. Sin dependencias externas, sin runtime que instalar, sin servicios de terceros. Lo bajas, lo ejecutas, y funciona.
El núcleo del sistema está respaldado por SQLite con FTS5, lo que permite búsqueda full-text en milisegundos incluso con cientos de pills acumuladas. Pero no es solo texto exacto: Pillbox implementa prefix matching y fuzzy matching con el algoritmo Jaro-Winkler, lo que significa que el agente puede encontrar conocimiento relevante aunque no recuerde la frase exacta que usó para guardarlo.
Esto importa más de lo que parece. Un sistema de memoria que solo busca texto exacto no sirve de mucho en la práctica. El valor real está en poder recuperar información de forma semántica, y eso empieza por una buena búsqueda aproximada.
Dentro del mismo binario tienes cuatro interfaces para interactuar con Pillbox:
- CLI: comandos directos para gestionar bottles, pills, capsules y el servidor
- MCP server: el bridge que conecta Pillbox con los editores compatibles. Está escrito en TypeScript y actúa como intermediario entre el protocolo MCP y el núcleo en Rust
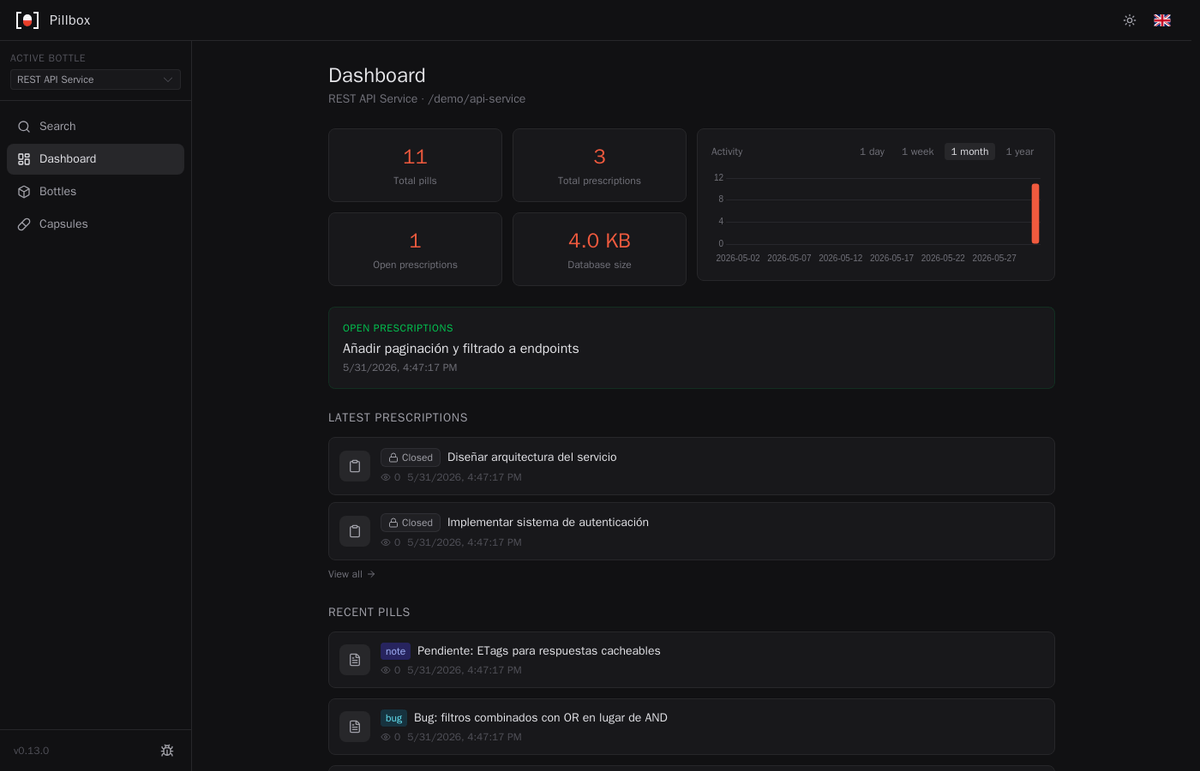
- Web UI embebida: interfaz visual accesible en
http://pillbox.local:4242sin instalar nada más - API HTTP: por si necesitas integrarlo con otras herramientas o automatizaciones
La web UI me tomó más tiempo del esperado 😅 Tenía claro que quería algo embebido en el propio binario, sin depender de archivos externos. Al final funciona exactamente como quería: arrancas el servidor y tienes una interfaz completa para revisar el conocimiento acumulado sin abrir el terminal.
El stack técnico
Rust fue la decisión más clara desde el principio. Como ya hablé cuando exploré Tauri, Rust te da rendimiento nativo con una fiabilidad que en otros lenguajes tienes que ganarte a base de tests y cuidado. Para un sistema de memoria que tiene que ser extremadamente rápido y estable, era la elección obvia.
SQLite como almacenamiento también fue una decisión fácil. Cero configuración, cero servidor externo, archivos portables. Cada bottle es un fichero .db en el directorio del proyecto. Puedes hacer backup, moverlo, compartirlo. Es tuyo.
El MCP server en TypeScript es el único componente que no es Rust. El Model Context Protocol tiene implementaciones de referencia en TypeScript y Python, y usar el ecosistema ya establecido aquí tiene más sentido que reinventar la rueda. El bridge habla HTTP con el núcleo Rust y expone las herramientas MCP al cliente.
En cuanto a compatibilidad, de momento funciona con Claude Code y OpenCode, en Windows, Linux y macOS. El protocolo MCP es un estándar abierto, así que ampliar el soporte a otros editores es cuestión de tiempo.
Y el sistema está localizado en seis idiomas: español, inglés, francés, alemán, italiano y portugués. Sí, desde el principio. Hacerlo después es mucho más costoso, y quería que Pillbox fuera útil para alguien en cualquier idioma desde el día uno.
La arquitectura en cuatro conceptos
Para quien no haya leído el artículo anterior, un resumen rápido de cómo se organiza el conocimiento. Están todos los detalles en el primer artículo si quieres profundizar.
- Bottle: un proyecto. Cada directorio de trabajo tiene su propio bottle con su SQLite.
- Prescription: una sesión de trabajo dentro de un bottle. El agente abre una al empezar y la cierra al terminar.
- Pill: una pieza de conocimiento ligada a un proyecto. Decisiones, bugs, patrones, hallazgos.
- Capsule: conocimiento personal y transversal, disponible en todos los proyectos. Tus convenciones, tu entorno, tus preferencias.
Tanto pills como capsules admiten un campo compound para categorizar el tipo de conocimiento. Pillbox no impone ningún vocabulario: los compounds que uses dependen del flujo agéntico que tengas configurado. El flujo que se distribuye con Pillbox propone una taxonomía concreta, pero si tienes tu propia forma de estructurar el contexto, puedes usar la que quieras.
Cómo instalarlo
Aquí va lo importante. El proceso de instalación está documentado en detalle en el repositorio, incluyendo instrucciones específicas para cada editor compatible y plataforma. Mejor apuntar ahí que repetirlo aquí y arriesgarse a que quede desactualizado.
→ Instrucciones de instalación en GitHub
Conceptualmente son dos pasos: descargar el binario (hay script para Linux, macOS y Windows) y registrar el servidor MCP en tu editor. Una vez hecho, el agente tiene acceso a todas las herramientas de Pillbox desde la siguiente sesión.
El flujo de trabajo
Lo que ocurre a partir de ahí depende del flujo agéntico que uses. Si quieres profundizar en qué significa trabajar con agentes de código, tengo un artículo sobre mi experiencia programando con inteligencia artificial que da buen contexto. Pillbox se distribuye junto a un conjunto de skills y definiciones de agentes pensado para que el agente gestione su propia memoria persistente de forma autónoma —abrir una prescripción al empezar, guardar conocimiento durante el trabajo, cerrarla al terminar— sin que tengas que intervenir.
Ese flujo está incluido y es el que recomiendo si no tienes ya uno establecido, pero no es obligatorio. Un desarrollador que prefiera gestionar la memoria de otra manera puede usar las herramientas MCP directamente o construir su propio flujo encima del núcleo.

Lo que me ha llevado más tiempo
Construir Pillbox con Pillbox desde bastante pronto en el proceso fue una decisión que ha tenido un efecto curioso: cada limitación que me molestaba como usuario la acababa resolviendo como desarrollador. Eso acelera mucho la iteración y ayuda a priorizar lo que de verdad importa frente a lo que solo parece importante sobre el papel.
Lo que más me ha costado no ha sido la parte técnica, sino definir exactamente cuánto conocimiento guarda el agente de forma autónoma y cuánto control le das al usuario. Si el agente guarda demasiado, el sistema se llena de ruido. Si guarda muy poco, no sirve de nada.
El equilibrio actual es el resultado de semanas de ajustes, probando en proyectos reales, incluyendo el propio desarrollo de Pillbox 😎
También dediqué más tiempo del esperado a la búsqueda. Implementar Jaro-Winkler encima de FTS5 no es trivial, y asegurarme de que los resultados sean relevantes sin ser ruidosos requirió bastante calibración. Pero es la parte del sistema de la que más orgulloso estoy: buscar en una base de conocimiento grande y obtener lo que necesitas en milisegundos, aunque no recuerdes exactamente cómo lo escribiste, cambia completamente la experiencia.
Conclusión
Pillbox ha pasado de ser un proyecto en construcción a algo que puedes instalar y usar hoy. Construido en Rust, sin dependencias externas, con búsqueda full-text y fuzzy matching, compatible con Claude Code y OpenCode, y con una web UI embebida para cuando necesitas una vista completa de la memoria persistente acumulada.
Si trabajas con agentes de IA y el problema te resulta familiar, esta es tu solución. El repositorio está en GitHub, la documentación está ahí, y si encuentras algo que no funciona o tienes feedback, los issues son el lugar.
Dale una oportunidad. Una vez que tu agente llega a un proyecto y ya sabe qué se hizo la semana pasada, no quieres volver atrás.